Abstract
We present a machine-learning benchmark for non-resonant vector-boson- fusion Higgs-pair production in the semileptonic channel HH → bbW W → bbqqℓν. From truth-level Monte Carlo samples, we build a selected and matched event-level dataset and represent each event with kinematic features for the main physics objects and their combinations. We then study whether this representation can distinguish different values of the coupling scan parameter cvv, with focus on the binary separation of the Standard Model reference point cvv = 1 from the remaining sampled classes. We find that this task is learnable with the available feature set. The full representation performs best overall, while several nonlinear models reach similar accuracy. In contrast, scaling and oversampling show mixed effects, and ensemble methods do not clearly improve on the best individual models. These results show that the matched event representation retains useful information for coupling classification in semileptonic VBF Higgs-pair events.
Physics Context

VBF Higgs-pair production is a rare process predicted by the Standard Model whose rate is
highly sensitive to the quartic coupling constant κ2V
(the cvv parameter). Since VBF HH production has not yet been observed, measuring
or constraining κ2V requires ML-assisted discrimination of events produced at the
SM point (cvv = 1) from events produced at anomalous coupling values.
We study the semileptonic decay channel HH → bb WW* → bb qq ℓν, producing two b-jets, two light jets, a charged lepton, and a neutrino. Events are processed through a full Delphes detector simulation and jet matching pipeline. The coupling scan covers cvv ∈ {0.0, 0.5, 1.0, 1.5, 2.0, 3.0}.
Class Imbalance (after matching)
| κ2V value | Class label | Matched events | Survival fraction |
|---|---|---|---|
| 0.0 | C0.0 | 243 917 | 12.20% |
| 0.5 | C0.5 | 180 456 | 9.02% |
| 1.0 (SM) | C1 | 19 796 | 0.40% |
| 1.5 | C1.5 | 209 702 | 20.97% |
| 2.0 | C2.0 | 204 740 | 20.47% |
| 3.0 | C3.0 | 185 928 | 18.59% |
Because all non-SM classes are nearly indistinguishable from each other (5-class accuracy ≈ 20%, equal to random guessing), the task is reduced to the binary problem: C1 vs. Cnot 1.
Dataset & Features
Each event is described by kinematic four-vector observables of the reconstructed physics objects, grouped by their role in the topology. In total 52 features are used (after dropping azimuthal angles and some jet-level duplicates that provide no discriminating power). The dataset (~1M events, CSV) is publicly available for download. ↓ Download dataset
Kinematics of the two forward tagging jets (pT, η, m, E, ΔR, jet-level).
System momentum and individual quark daughters from the W → qq decay.
Charged lepton and neutrino four-vector components.
Jet-level and b-jet daughter kinematics of the Higgs decaying to b-quarks.
Derived quantities built from multiple objects: HH mass, ΔR distances, invariant masses.
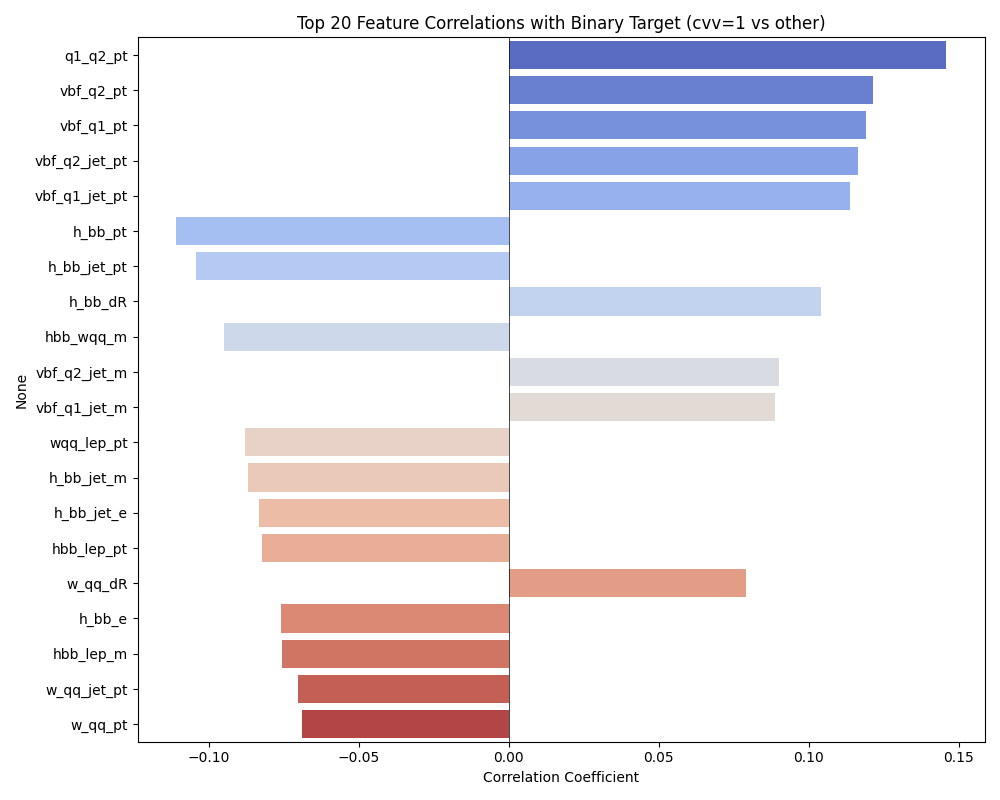
Feature Distributions
Select a particle and a property to explore the per-class distributions. C1 (SM, cvv=1) is shown in red, Cnot1 in blue. Most variables show substantial overlap — the coupling signal is a small shape distortion. The clearest separation appears in pseudorapidity (η) of the VBF tagging jets.
Models Overview
All classical ML models are implemented with scikit-learn and run through the same config-driven framework. The PyTorch MLP uses residual connections, batch normalisation, and optional SE blocks. DeepSets operates on sets of events.
Results
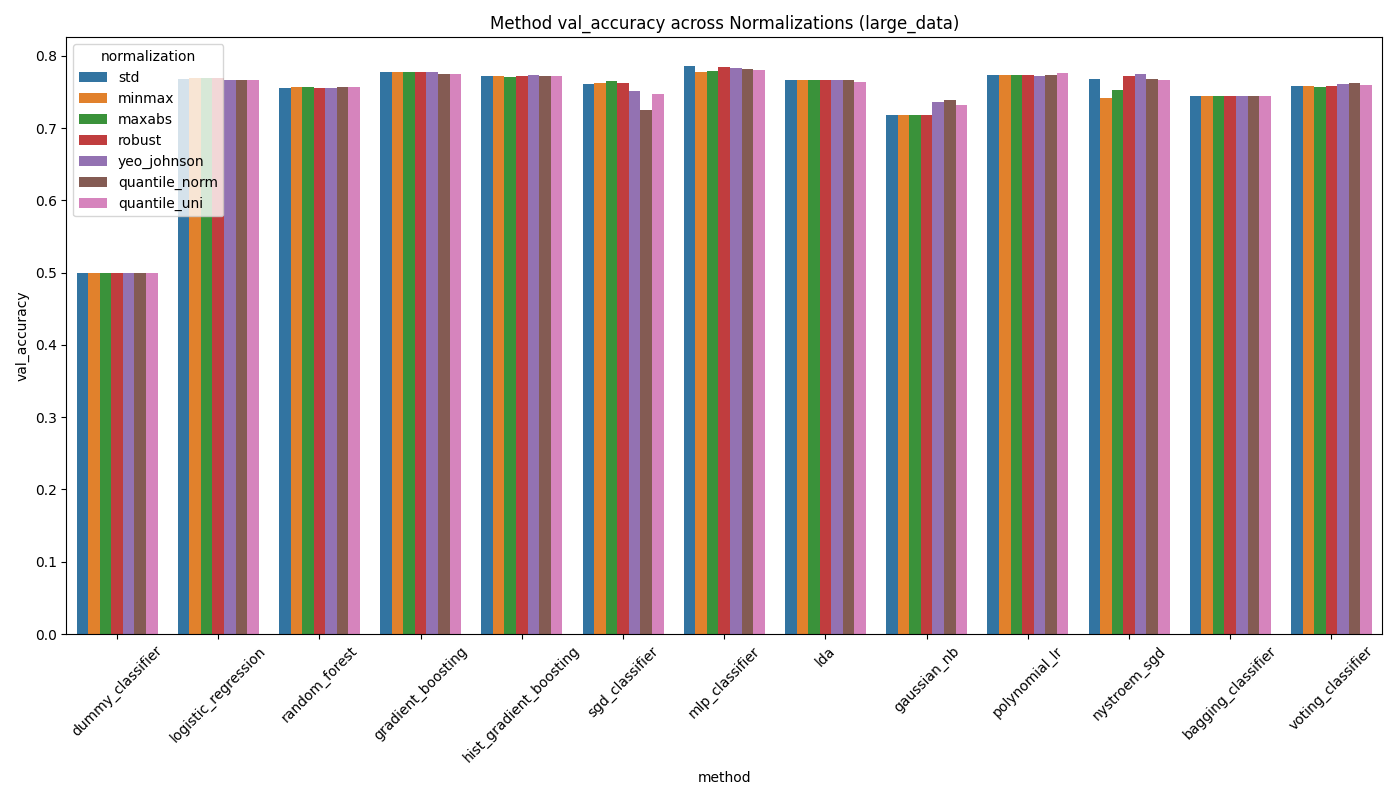
After sweeping all preprocessing combinations we identify the single best configuration per model. Toggle between the chart and a summary table below.

- All models cluster tightly in the 74–79% range when tuned to their best settings, suggesting the bottleneck is the data rather than the choice of model.
- The MLP achieves the highest accuracy at 78.64%, outperforming the second-best (Gradient Boosting, 77.86%) by only 0.78 percentage points.
- Standard scaling + 3× oversampling is the most common winning preprocessing combination across models.
- Gaussian NB is the clear outlier, limited by its Gaussian feature assumption, but still reaches 74%.
Feature scaling transforms each column to a common numerical range before training. We compare 7 strategies: Standard (STD), MinMax, MaxAbs, Robust, Yeo-Johnson, Quantile (normal), and Quantile (uniform). For neural networks and distance-based methods, scaling is critical because gradient updates are dominated by large-magnitude features otherwise. Tree-based models are theoretically invariant but can still be affected in practice through interaction with regularization.
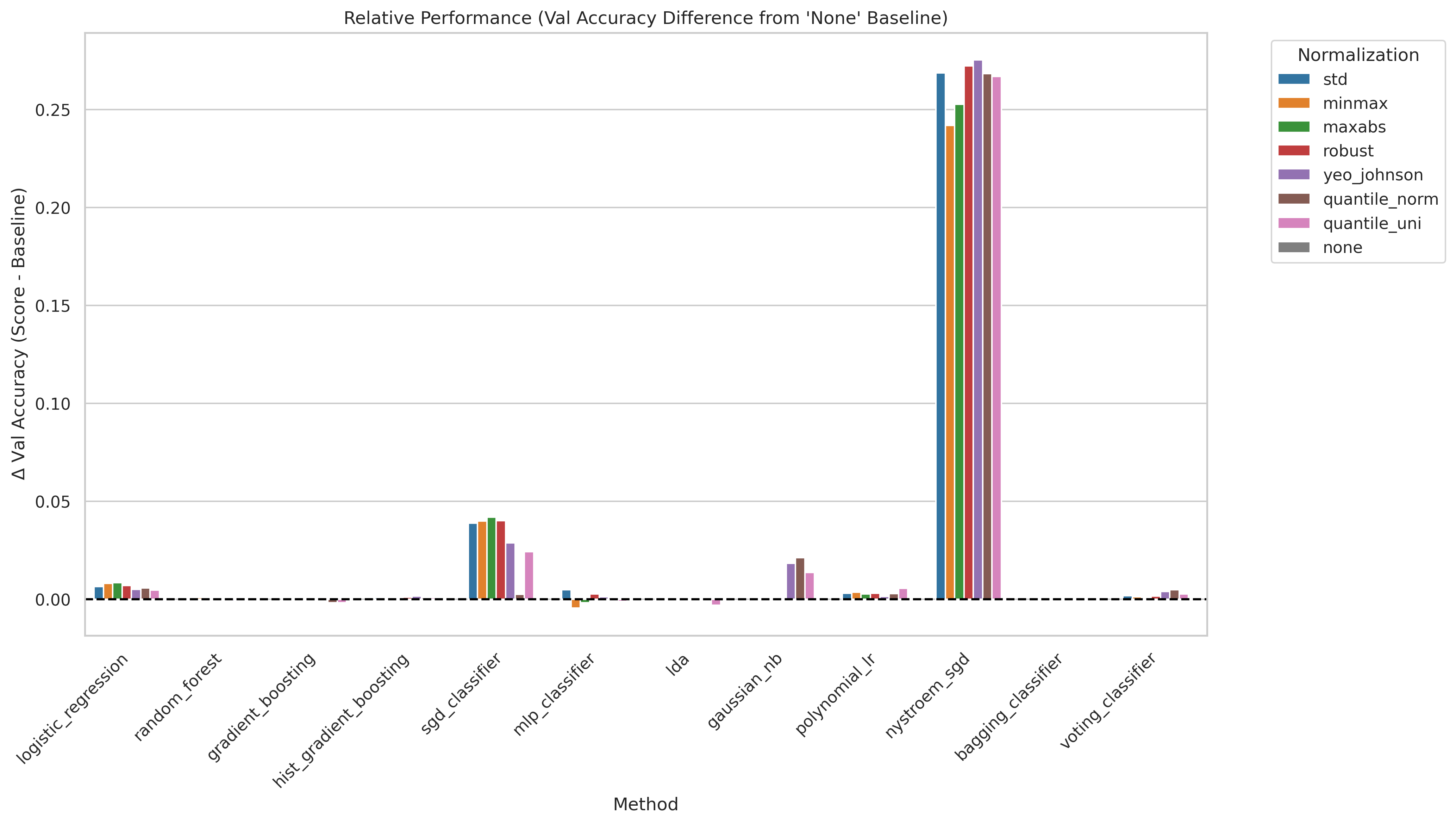
- Standard scaling is a safe default — it either wins or ties with more exotic strategies for nearly every model.
- Tree-based models (Random Forest, Gradient Boosting) are largely insensitive to the scaling choice, as expected from their split-based nature.
- The MLP benefits most from standard scaling; Yeo-Johnson and quantile transforms offer no consistent improvement and occasionally hurt.
- Gaussian NB is an exception: it benefits from quantile normalization because its Gaussian assumption is better satisfied after that transform.
Per-sample (row-wise) normalization scales each individual event vector to unit norm after column-wise scaling. We test four variants: no normalization, L1 norm, L2 norm, and Max norm. The idea is to remove scale differences between events, which can help when the overall magnitude of a feature vector carries no class-discriminating information.
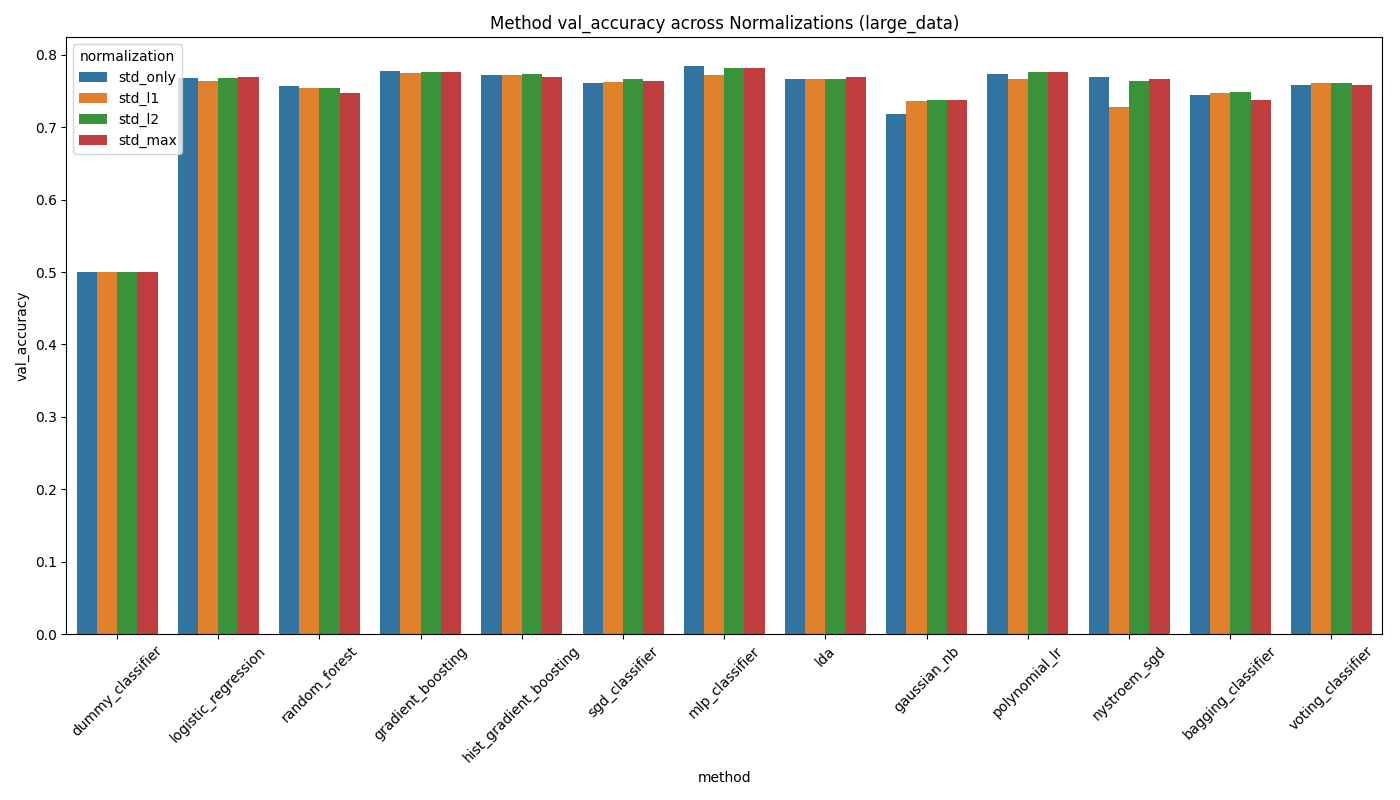
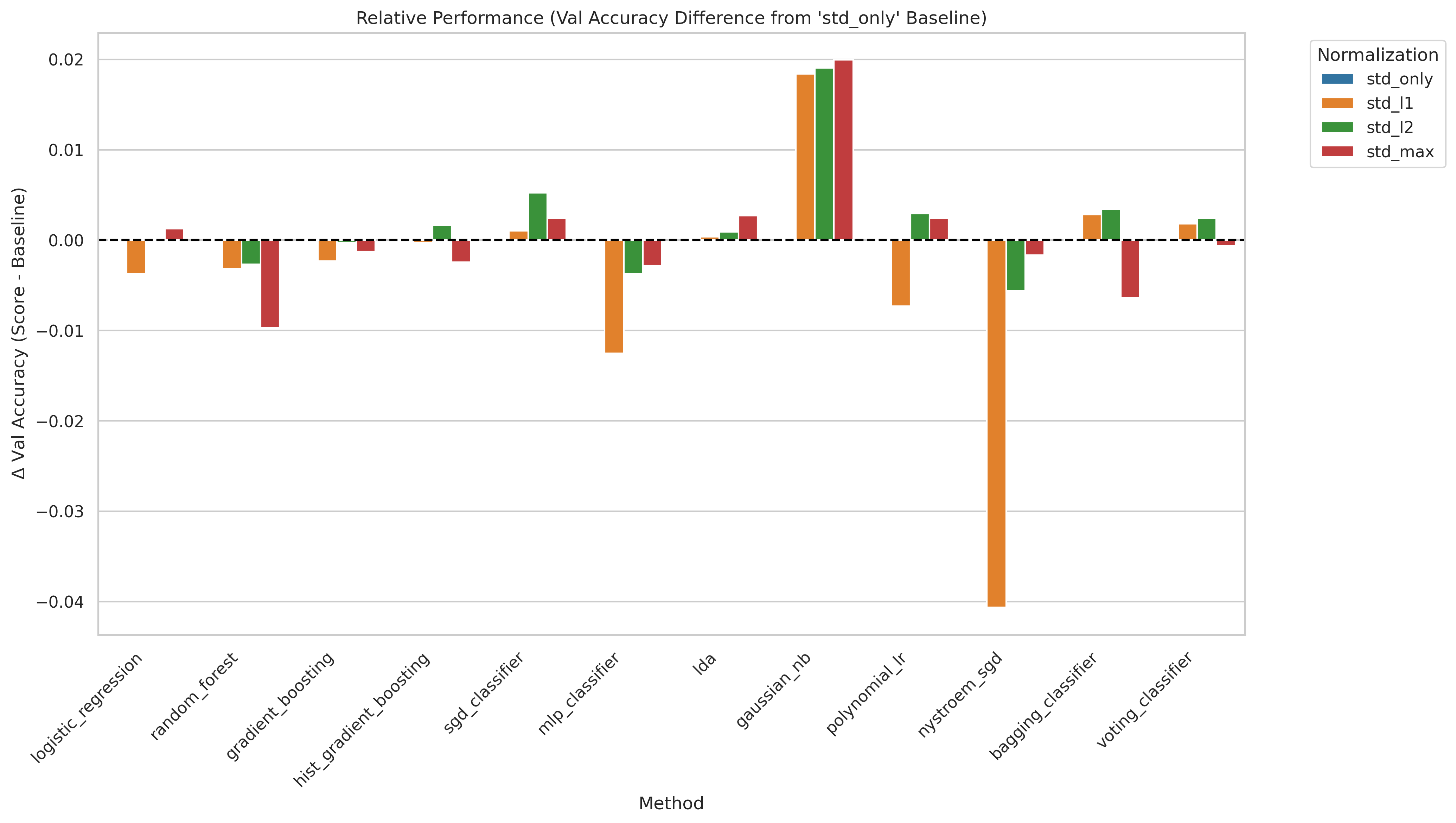
- Per-sample normalization provides no meaningful benefit for most models — the differences are within noise.
- Only Gaussian NB shows a consistent improvement with L2 normalization, because normalizing the event vector better satisfies its independence and Gaussian assumptions.
- For some models (MLP, GBT) normalization slightly hurts, likely because it destroys the absolute scale information that carries class-relevant signal (e.g., total event energy).
- Recommendation: skip per-sample normalization unless specifically using Gaussian NB.
We compare three feature sets: all features (52 variables including combination observables), old features (basic kinematic four-vectors only, no derived quantities), and new features (the combination observables alone). The combination features are derived quantities involving multiple reconstructed objects — such as the HH invariant mass, ΔR distances between systems, and multi-object invariant masses — motivated by their expected sensitivity to the coupling structure.
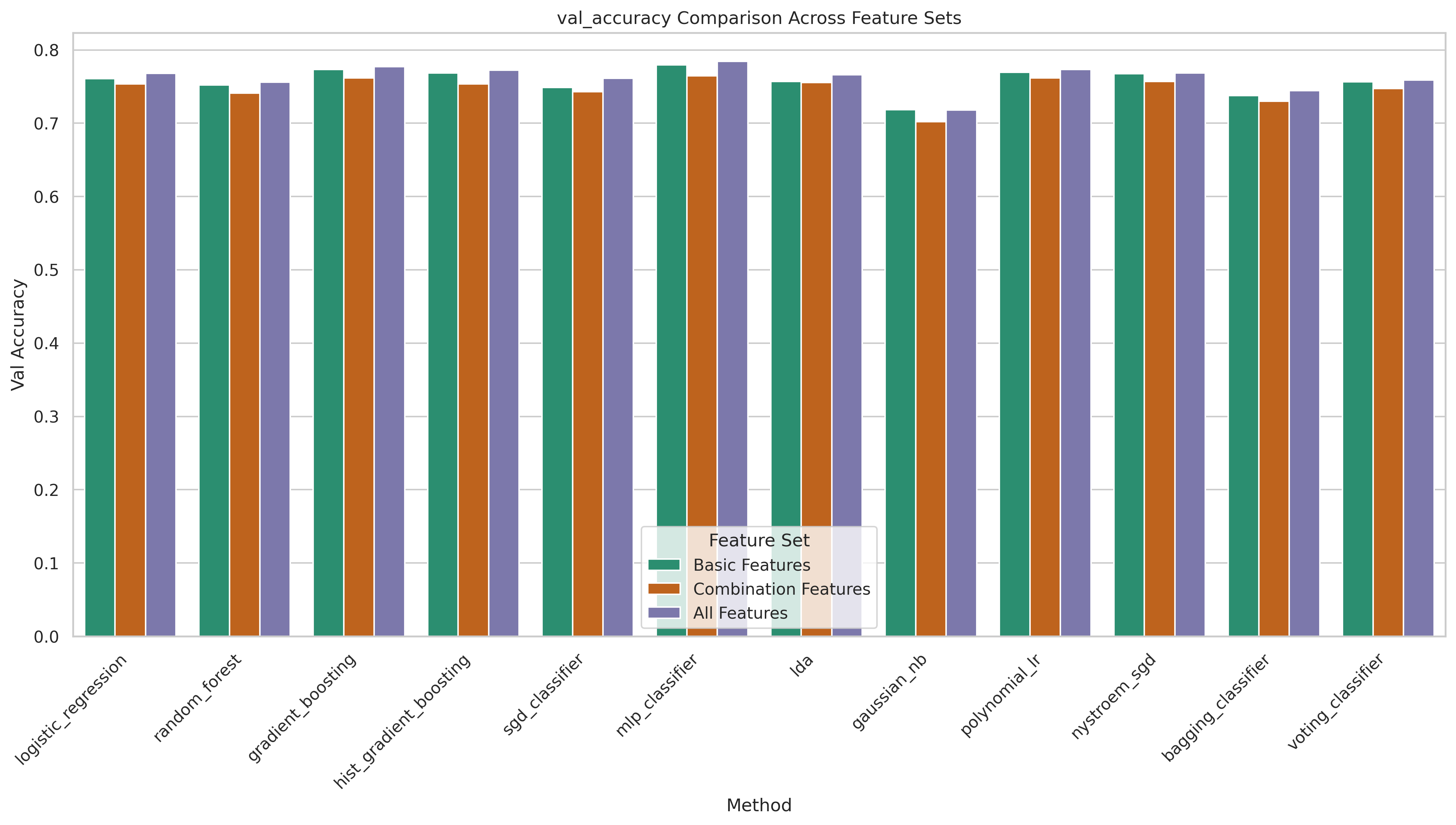
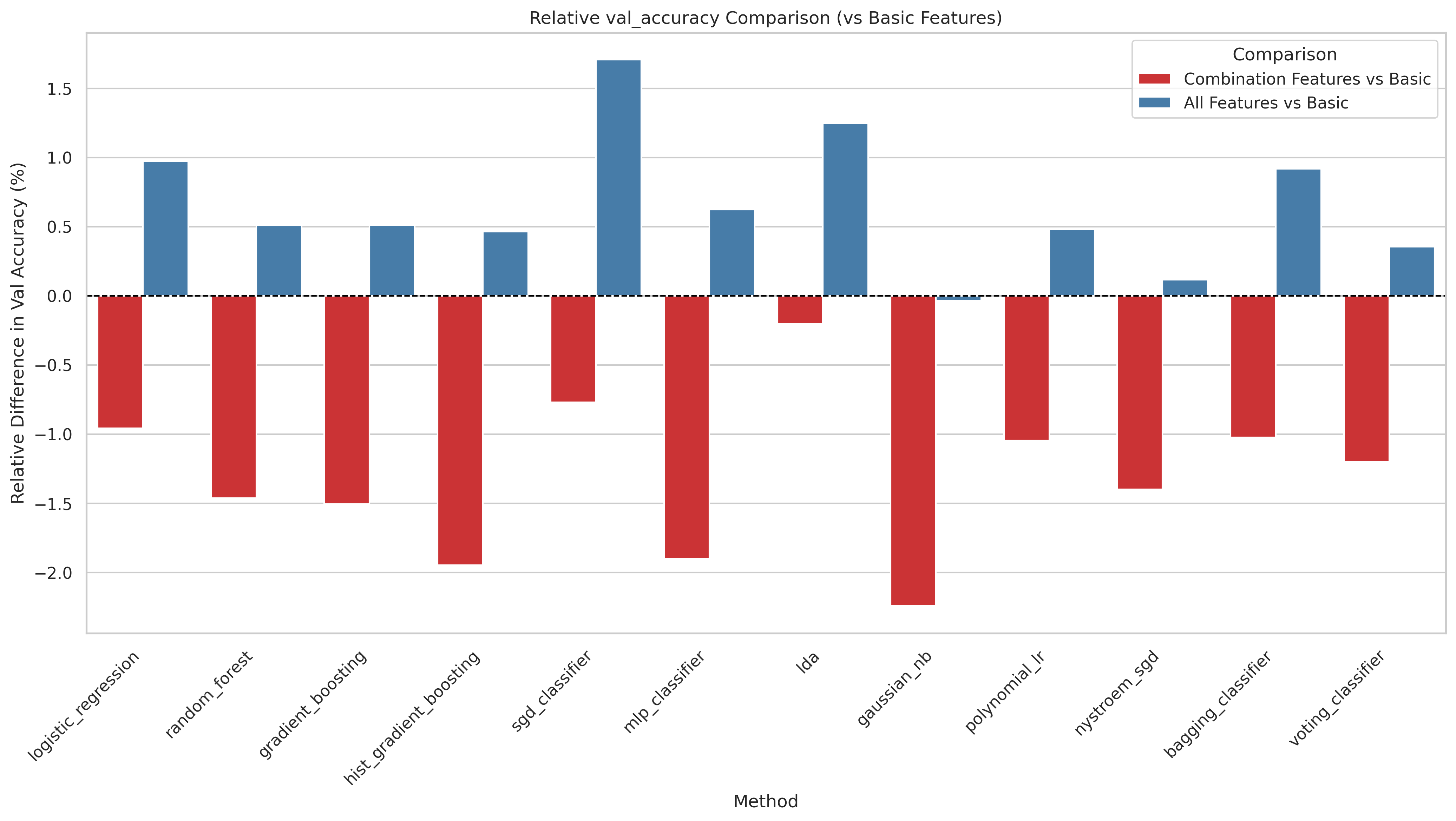
- Using all features is consistently the best or tied-best choice.
- Combination features add up to ~1.7% accuracy for some models over basic kinematics alone.
- The combination features alone (without basic kinematics) perform significantly worse, confirming they complement rather than replace the basic four-vector information.
The Standard Model class (cvv = 1) has only 0.4% matching survival, leading to a severe class imbalance. We compare three strategies: undersampling (reducing the majority class to match the minority), 3× oversampling (SMOTE-style duplication of the minority class to 3× its original size), and 10× oversampling.
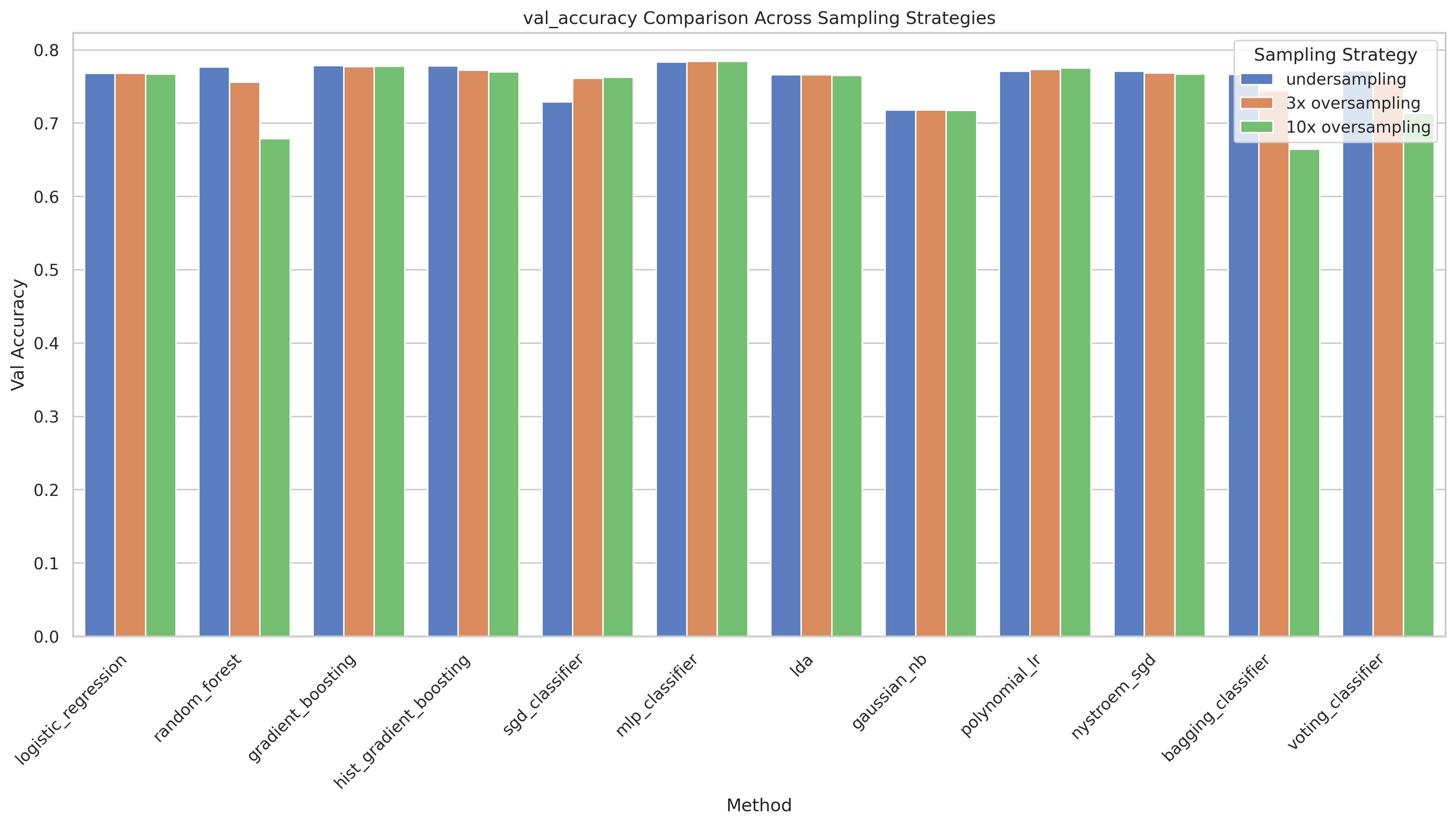
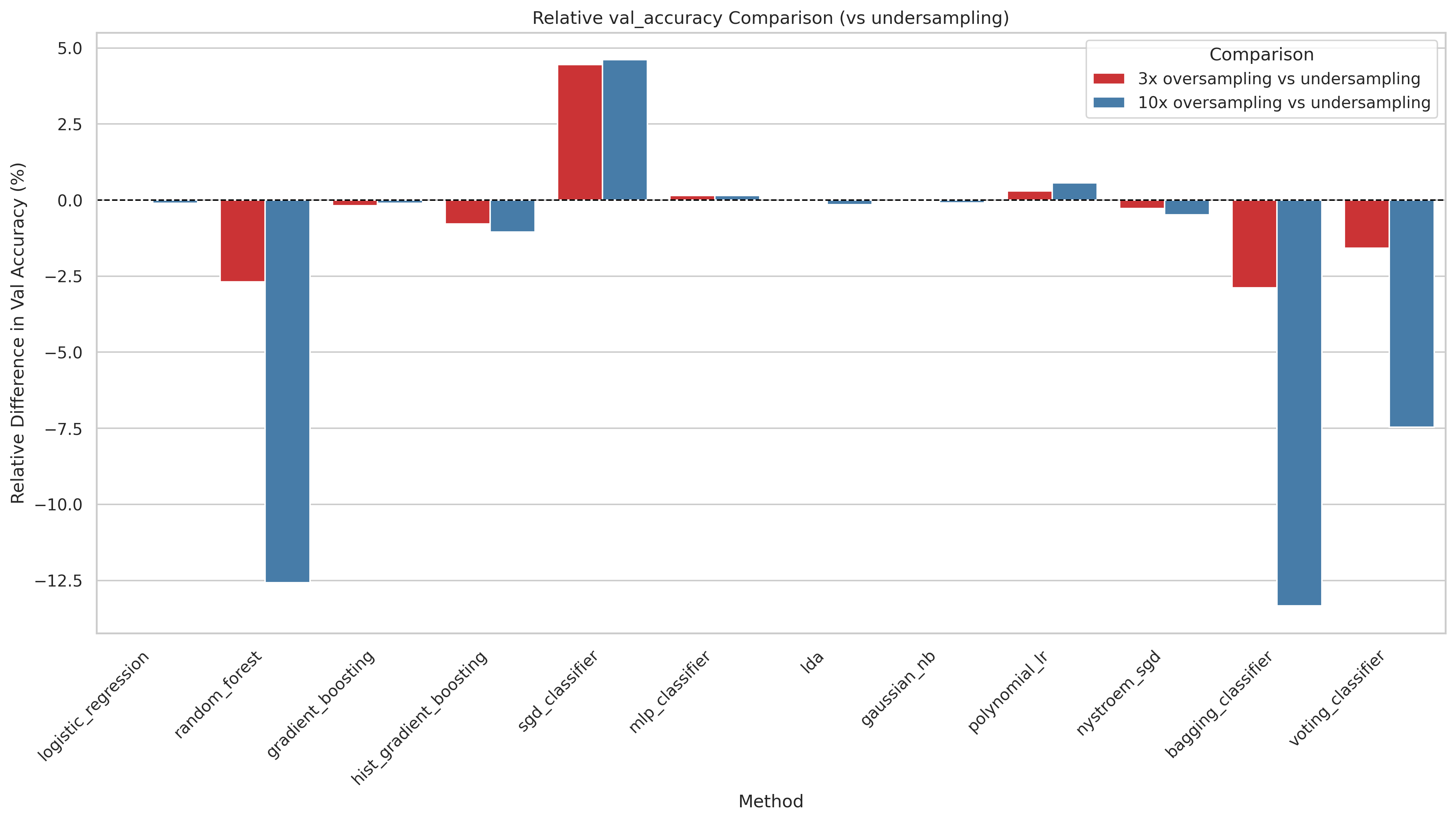
- 3× oversampling surprisingly only improves the SGD classifier significantly. This suggests that more data from the majority class doesn't improve performance.
- Undersampling is surprisingly competitive and wins for tree-based models (GB, HistGBT, Random Forest), likely because it produces a cleaner, balanced dataset that those methods handle well.
- 10× oversampling consistently hurts: the minority class is repeated so many times that models memorize it, leading to overfitting and worse generalization.
Ensemble methods combine predictions from multiple individually trained models via majority voting. The idea is that if models make different errors, a vote can cancel individual mistakes and improve overall accuracy. We test diverse combinations of the best-performing models (MLP, GBT, HistGBT, Random Forest, Logistic Regression) and measure both accuracy and macro F1 of the ensemble versus the individual member models.
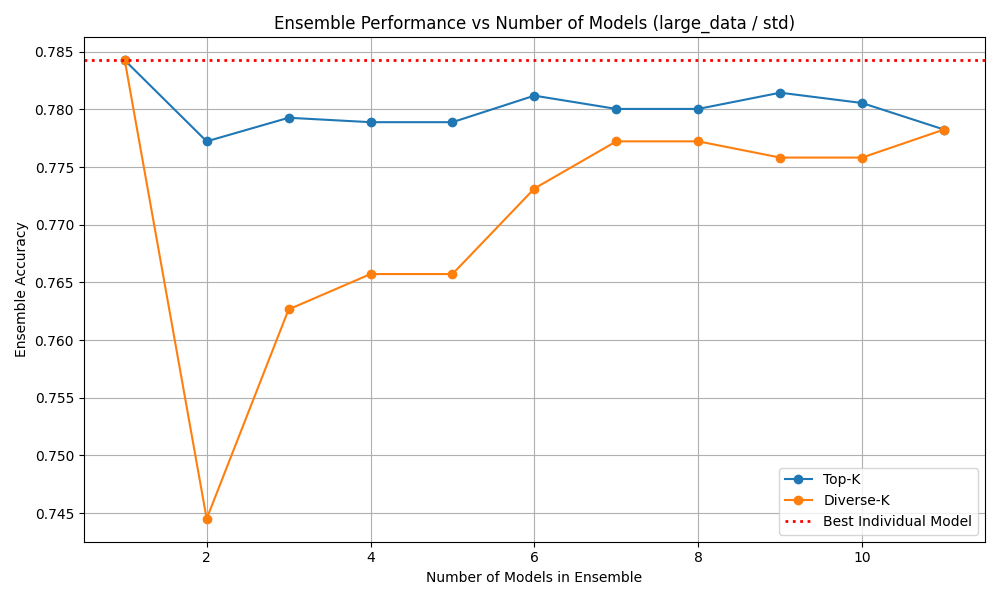
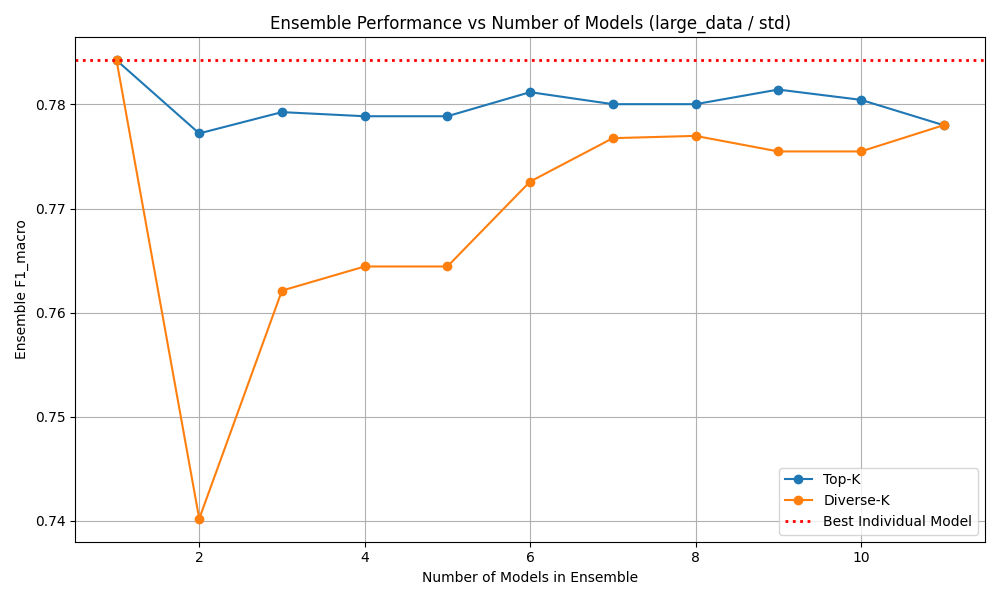
- No ensemble combination outperforms the best individual model. The MLP alone at 78.64% is not beaten by any voting ensemble.
- High pairwise model agreement (≥ 92% for MLP + GBT) leaves no room for diversification — all models agree on the same predictions, both correct and incorrect.
- This strongly implies that the models all learn from the same feature structure and hit the same information ceiling imposed by the data.
- Ensemble methods are not a viable path to improving performance on this task without fundamentally new information (e.g., multiple events).
DeepSets is a permutation-invariant architecture that classifies a set of N events simultaneously rather than one at a time. Each event is encoded independently through a shared MLP, then the encoded representations are aggregated (via max pooling, attention pooling, or self-attention) before a final classification head. Because all N events share the same underlying coupling parameter, using multiple events per prediction provides a statistical averaging effect that makes the coupling signal much clearer.
| Set size N | Accuracy | Precision | Recall |
|---|---|---|---|
| 1 | 77.58% | 77.57% | 77.56% |
| 2 | 86.09% | 85.22% | 85.21% |
| 3 | 90.27% | 90.48% | 90.47% |
| 5 | 95.51% | 95.28% | 95.28% |
| 10 | 99.11% | 98.82% | 98.82% |
- Accuracy scales sharply with set size: from 77.6% at N=1 to 99.1% at N=10, a gain of over 21 percentage points.
- This confirms that while the coupling signal in any single event is weak, it becomes statistically unmistakable when integrated over multiple events — exactly the regime of a real experimental analysis.
- An ablation over aggregation strategies (self-attention, attention pooling, max pooling) shows no significant difference: simple max pooling already captures all the relevant information, and self-attention provides no additional benefit.
- The comparison with single-event models is not directly fair (more input information per prediction), but the result motivates set-level inference as a powerful strategy for coupling classification.
Conclusion & Outlook
This study demonstrates that binary discrimination of VBF HH events at the Standard Model coupling point from all other coupling values is achievable with classical ML, but is genuinely difficult due to extreme class imbalance and limited signal in single-event representations.
Standard scaling and 3× minority oversampling form a robust preprocessing baseline. Adding combination features (derived multi-object quantities) gives small but consistent improvements. No ensemble combination outperforms the best individual model, confirming that all methods exploit the same feature correlations.
The most striking result is from DeepSets: classifying sets of 10 events simultaneously reaches 99.1% accuracy, compared to 77.6% for a single event. This suggests that while the coupling signal in a single event is weak, it becomes highly statistically significant when integrated over multiple events — exactly the situation in a real experimental analysis.
Limitations & Future Work
All results are based on truth-level simulation without detector effects. No held-out test set was used; all reported numbers come from the validation split. Future work could apply the framework to detector-level data, use larger datasets, or investigate whether the strong DeepSets results hold under more realistic experimental conditions.
@techreport{benchmark2025vbf,
author = {Foerster, Felix and Schneider, Lars and Mesner, Johannes and Linden, Lars and Stauch, Celine},
title = {A Machine-Learning Benchmark for Semileptonic VBF Higgs-Pair
Events in a Coupling Scan},
institution = {Technical University of Munich / LMU Munich},
year = {2025},
url = {https://spatenfe.github.io/vbf_event_classifier/}
}